编译与链接
本文整理自之前我在公司内部培训上的演讲ppt
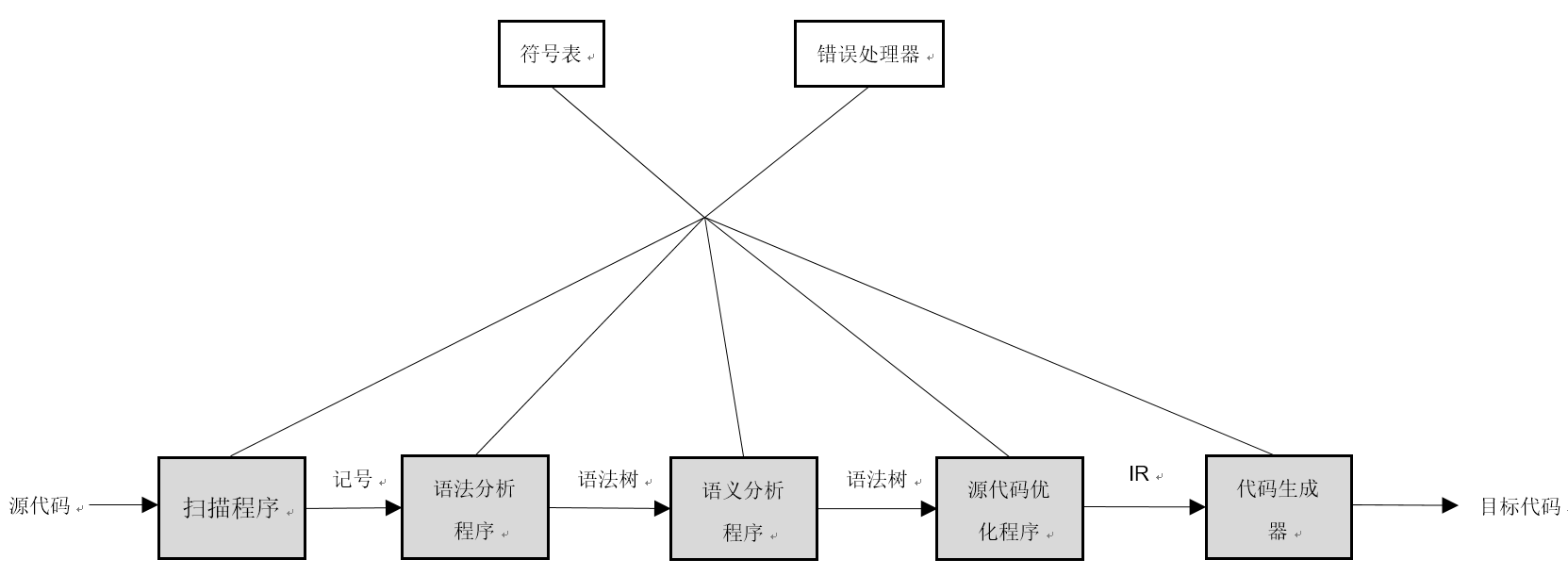
编译概要
阶段:
- 词法分析
- 语法分析
- 语义分析
- 代码优化
- 代码生成
划分:
- 编译前端,包括词法分析、语法分析、语义分析
- 编译后端,包括代码优化、代码生成
流程:
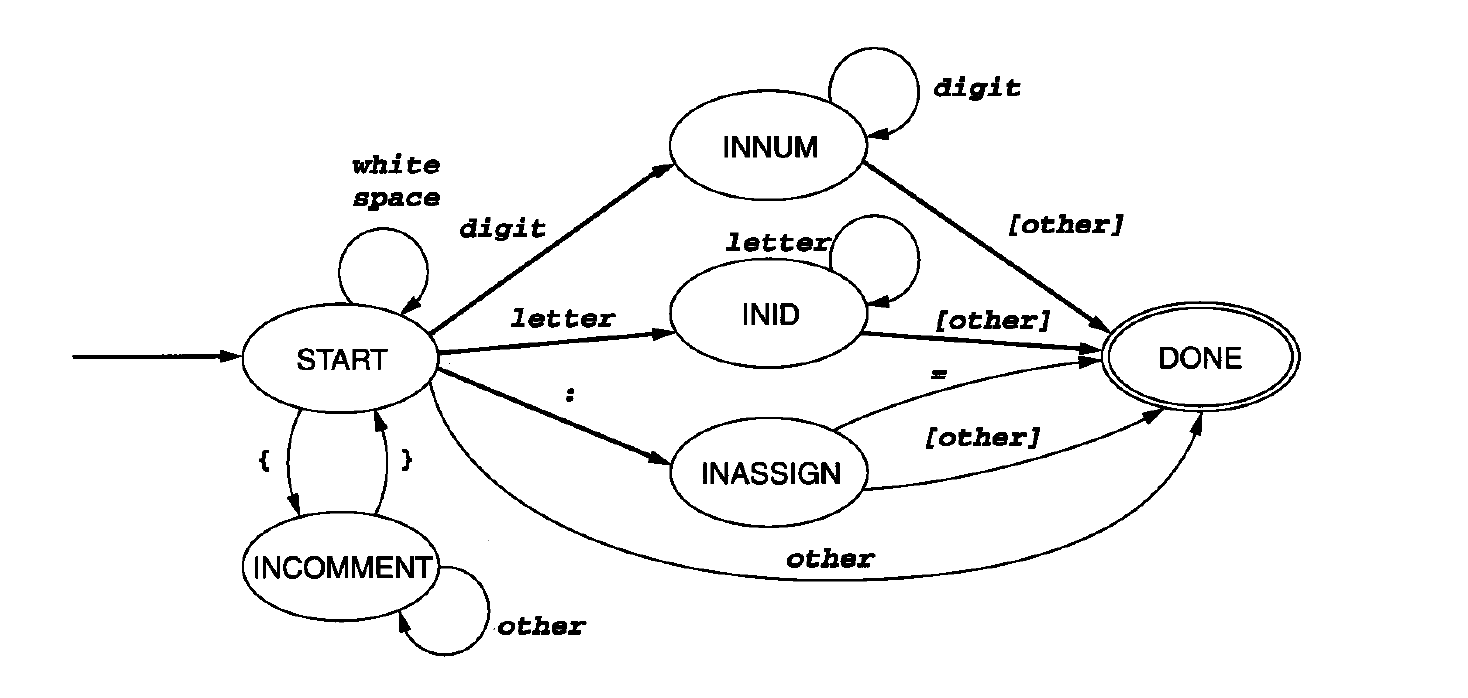
词法分析
将输入的字符串流转换为特定的token
识别字符组合的过程
- 标识符
- 关键字
- 数字
- 操作符
- 忽略注释
直接构造DFA(确定性有限自动机)
- 直接,适合暴力手写词法分析
- 复杂的词法结构不易直接构造出来
从正则表达式到NFA(非确定性有限自动机),再从NFA构造DFA
- 复杂情况下适合使用,因NFA容易构造,但需编写特定算法(例如子集构造)从NFA构造DFA
- 词法分析生成工具(如Lex)
- 正则表达式引擎
DFA:
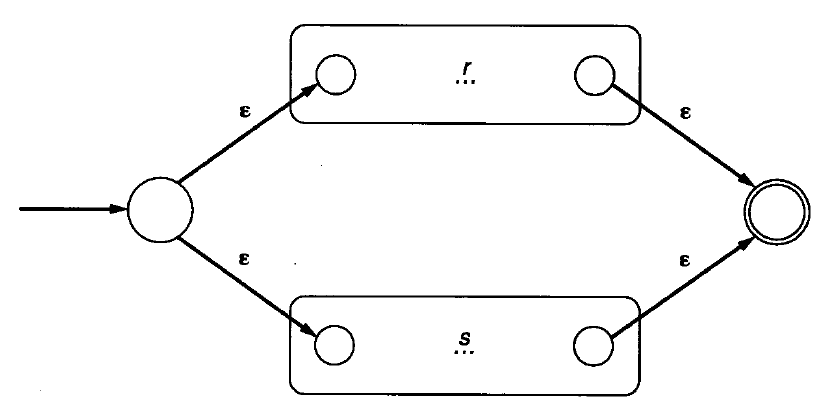
NFA:
- 并置

- 选择
- 重复
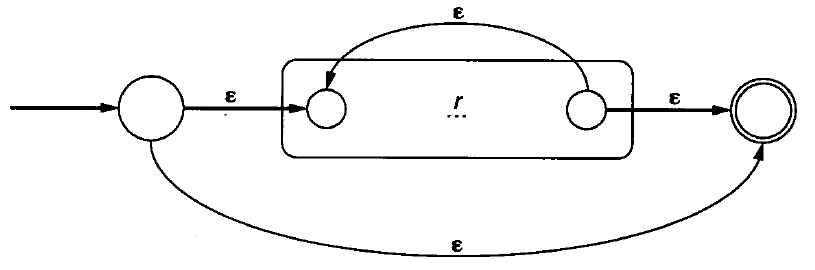
语法分析
将token流转换成语句,然后根据语句构造抽象语法树(AST)
例如if (bool_expression) {statement }就是简单的if语句,构成它所需要的token有关键字if,符号(,表达式,符号),符号{,语句statement,符号}。而这里表达式和语句又由token流组成,丢弃掉后续过程不关心的符号( ){},然后再由这些token及相关信息构造抽象语法树
乔姆斯基谱系
乔姆斯基谱系分为4层:
- 0型文法,无限制文法,该类型的文法能够产生所有可被图灵机识别的语言
- 1型文法,上下文相关文法,生成上下文相关语言。这种文法的产生式规则如αAβ-> αγβ一样的形式。这里的A是非终结符,而α、β、γ是包含非终结符和终结符的字串,α、β可以是空串,但γ不能是空串,该文法也可以包含规则S-> ε,但此时文法的任何产生式都不能在右侧包含S。这种文法规定的语言可以被线性有界非确定性自动机接受
- 2型文法,上下文无关文法,生成上下文无关语言。这种文法的产生式规则取如A-> γ一样的形式。这里的A是非终结符,γ是包含非终结符和终结符的字串。这种文法规定的语言可以被下推自动机接受。上下文无关文法是程序设计语言的理论基础
- 3型文法,正规文法,生成正规语言。这种文法要求产生式的左侧只能包含一个非终结符,产生式的右侧只能是空串、一个终结符或者一个非终结符后跟一个终结符。如果所有的产生式右侧都不包含初始符号S,规则S -> ε也允许出现。这种文法规定的语言可以被有限自动机接受,也可以通过正则表达式来获得。正规语言通常用来定义检索模式或者程序设计语言中的词法结构
| 文法 | 语言 | 自动机 | 产生式规则 |
|---|---|---|---|
| 0-型 | 递归可枚举 | 图灵机 | α -> β(无限制) |
| 1-型 | 上下文相关语言 | 线性有界非确定性图灵机 | αAβ -> αγβ |
| 2-型 | 上下文无关语言 | 非确定下推自动机 | A -> γ |
| 3-型 | 正规语言 | 有限状态自动机 | A -> αB 或 A -> α |
所有编程语言基本都属于上下文相关文法或者上下文无关文法的范畴,而编译器使用上下文无关文法分析方式 + 语义分析来确定这些语言的文法
上下文无关文法分析:
- 自顶向下分析,包括递归下降、LL(1)、LL(k)等分析方式
- 第一个L从左向右处理输入,第二个L表示最左推导
- 递归下降适合手写,并且比较自由,也适合处理复杂的语法结构,目前主流商业编译器使用,如gcc、clang、Visual C++等编译器
- 自低向上分析,包括LR(1)、LALR(1)等分析方式
- LR(1)、LALR(1)主要用于语法分析生成器(ParserGenarator)、如yacc(LALR(1))
正规文法,正则表达式所表示的语言属于正规语言,可用于词法分析,如正则表达式->NFA -> DFA -> token
递归下降分析
递归下降分析的概念非常简单,即将一个非终结符A的文法规则看作是识别A的一个过程
下面是用BNF表示的例子
exp → exp addop term | term |
由于上面的文法用递归下降分析会出现左递归,把其中2个产生式改写成EBNF形式可消除左递归
exp → term { addop term } |
处理exp:
function exp : syntaxTree; |
处理term:
procedure term; |
处理factor:
procedure factor; |
下面是一段求n的阶乘的代码:
read x; {input} |
经过语法分析后生成的抽象语法树:
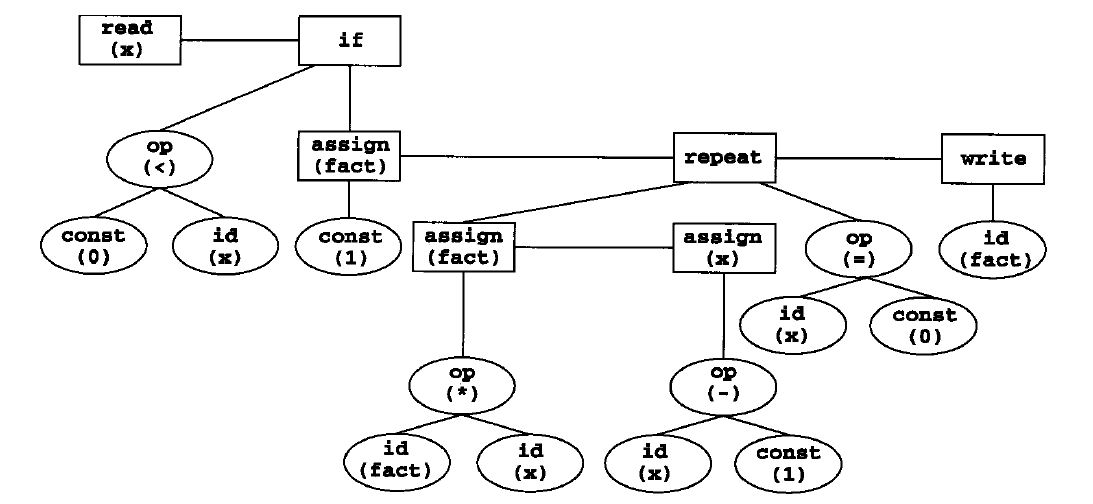
语义分析
在进行下一步之前,需要对抽象语法树进行分析,如类型检查、类型推导
在进行语义分析的时候,需要符号表来记录变量以及对应的类型,然后在遍历抽象语法树的时候来进行查询与处理
语义分析的输入是抽象语法树,输出仍然是抽象语法树
属性计算
合成属性
- 常量合并、类型计算、类型检查、类型转换
- 后序遍历AST
继承属性
- 整数的base值
- 前序遍历或者前序/中序遍历的组合
混合属性
- 合成属性依赖于继承(及其其他合成属性),但继承属性不依赖于任何合成属性,那么一遍中序遍历AST计算即可
- 其他混合属性可能需要多遍遍历AST
符号表
一般实现为hash表或者由hash表为基本元素构成的数据结构,如hash表树/hash表链表
符号表条目
- Hash link(可选)
- name
- category
- scope level
- type
- other(包括指向函数参数条目的指针,undef是否本模块定义等等)
嵌套作用域问题可以用scope stack来解决:

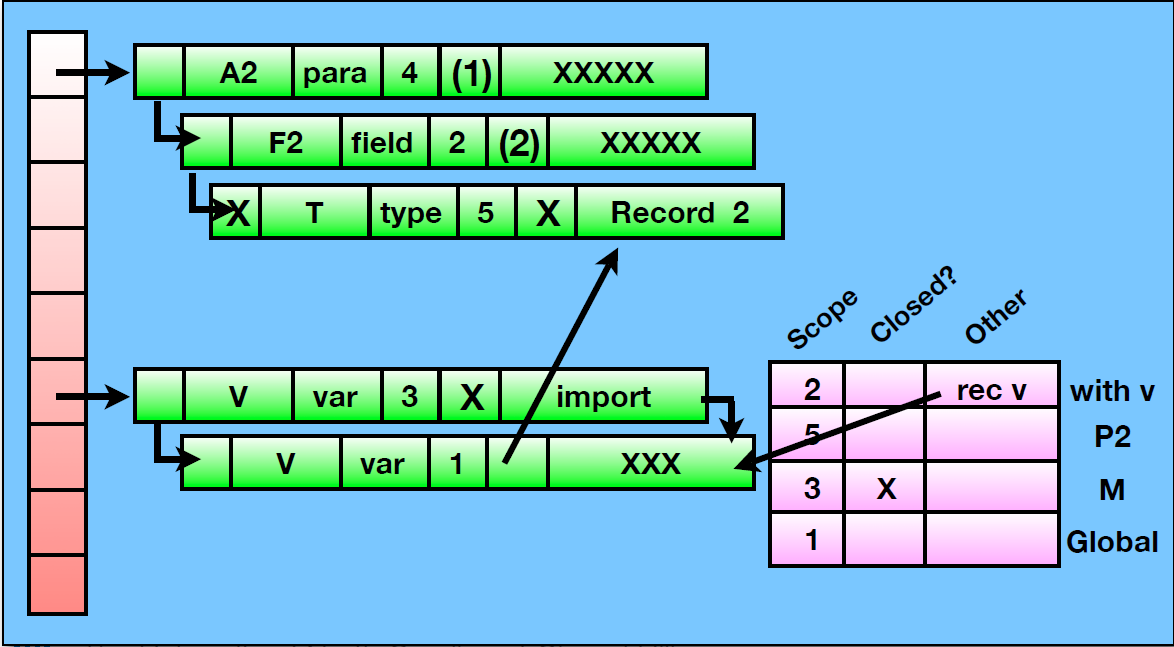
代码优化
优化来源:
- 寄存器分配,同样的代码64位编译比32位快(通用目的寄存器由8个增加到16个,函数调用传参最多可由6个寄存器传参而不需要存放在栈上)
- 不必要操作,消除不可达代码
- 高代价操作,常量合并、位运算替换普通计算、尾递归转换为循环、循环展开以提高单个cpu内部流水线的并行性
- 预测程序的行为
分类:
- 局部优化,如常量合并
- 区域优化,如循环展开、循环内常量计算代码移动
- 全局优化,如数据流分析、常量传播
- 过程间优化,如内联替换
代码生成
目标语言
- 直接翻译到目标语言
中间表示(IntermediateRepresentation, IR)
- 线性IR
- 堆栈代码,单地址代码,假定操作是存在一个栈中,大多数操作从栈获得操作数,并将其结果入栈
- 三地址代码,四元组(操作指令,目标,操作数1,操作数2)
- 图IR
- 抽象语法树,有向非循环图(共享机制的AST,相同子树只实例化一次并且可能有多个父节点)
- 控制流图(基本程序块为节点的有向图),通过控制流分析对程序中各个基本块之间的控制流建立了模型,数据流分析/指令调度/寄存器分配方面的优化都会用到
- 依赖关系图(可能依赖于控制流图),表示值从创建之处到使用之处的流动,指令调度优化会用到
- 调用图,优化跨越过程边界效率低下的问题,主要数据流分析中的过程间分析
机器语言
- 直接翻译成机器码
虚拟机
寄存器式虚拟机
- 表示程序逻辑所需的指令条数较小
- 简易实现中数据的移动拷贝次数较少
- 从源代码生成的难度大一些(寄存器分配)
- 解释执行速度较快(相较于栈式虚拟机)
- Lua
栈式虚拟机
- 从源代码生成的难度较小
- 表示程序逻辑的代码大小较小
- 解释执行速度慢一些
- JVM的解释执行部分、CPython
即时编译(JustIn Time Compiler, JIT)
- 把热点源代码直接编译成机器码给cpu执行,而不是让虚拟机解释执行中间代码(或者说是字节码)
- 提高执行效率,比如使用JIT技术的PyPy的执行速度大约是CPython的6.3倍
- JVM、V8引擎、PyPy
链接概要
链接是将各种代码和数据部分收集起来并组合成一个单一文件的过程,这个文件可被加载到存储器并执行
链接执行时间
- 编译时,也就是在源代码被翻译成机器代码时,静态链接
- 加载时,也就是程序被加载器加载到存储器并执行时,动态链接
- 运行时,由应用程序来执行,dlopen
链接使得代码文件的分离编译成为可能
目标文件
- 可重定位的目标文件
- 可执行的目标文件
- 共享目标文件
每个可重定位的目标模块都有一个符号表,它包含该模块所定义和引用的符号的信息,对于链接器来说有三种不同的符号
- 本模块定义并能被其他模块引用的全局符号
- 其他模块定义并被本模块引用的全局符号(外部符号)
- 只被本模块定义和引用的本地符号(static普通函数、static全局变量、匿名namespace中的符号都属于本地符号)
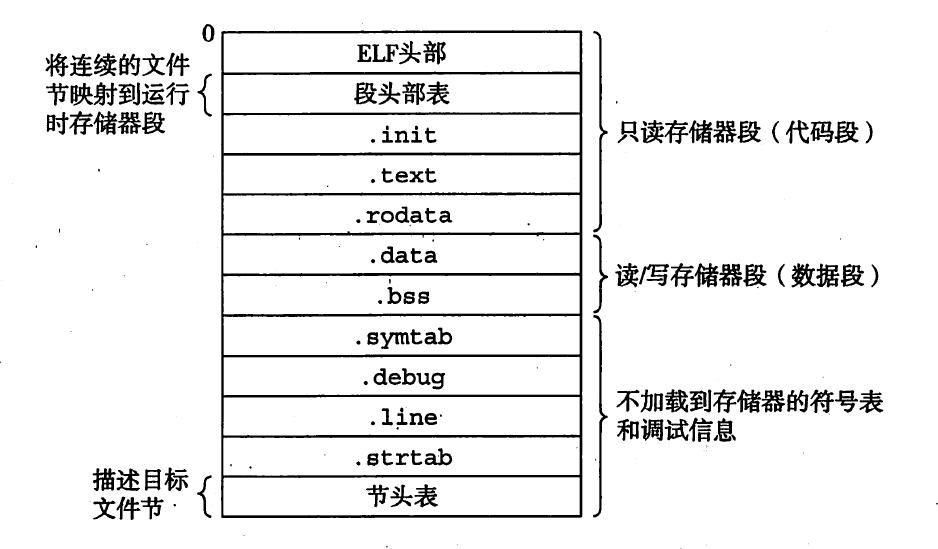
ELF格式可重定位的目标文件的结构如下:
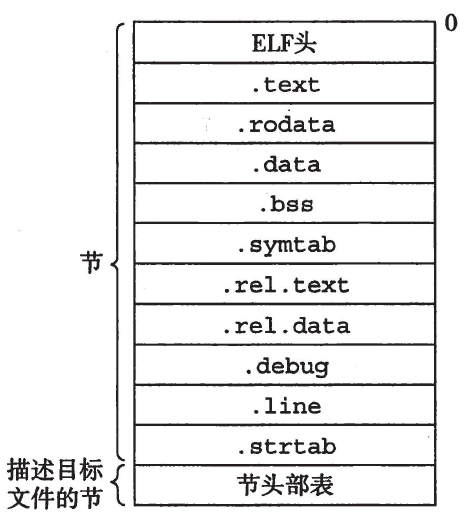
符号解析
链接器按命令行上从左到右的顺序处理输入文件,在整个符号解析过程中,维持3个集合,可重定位的目标文件集合E,未解析定义的符号集合U,已定义的符号集合D,初始状态这三个集合都是空的
- 每读入一个文件就更新这3个集合,并在D中寻找U中的符号,然后做相应的修改
- 读入的是库文件,就在库文件定义的符号中搜索U中的符号,若库文件中的某个目标文件定义匹配成功,则把该目标文件加入到E中,然后反复进行这个过程,直到U和D都不再发生变化,此时库文件中任何不包含在E中的目标文件都被丢弃
- 扫描所有输入文件后,若U非空,链接器输出错误并终止
命令行编译链接时的问题
- 引用某个符号的目标文件或者库文件需要出现在定义改符号的目标文件或者库文件的前面
- 如果几个库文件直接有互相引用,那么需按先引用再定义的顺序排序
静态链接
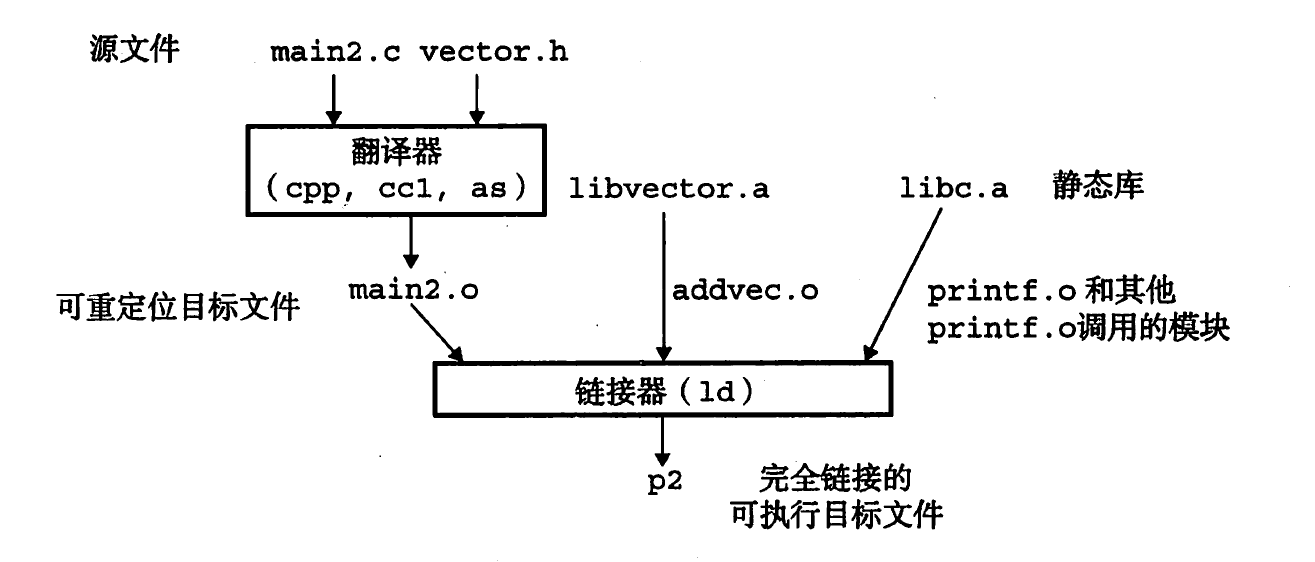
重定位
重定位节和符号定义
- 链接器将所有相同类型的节合并为同一类型的新的聚合节
- 将每个新的节的运行时地址存在段头部表中,并且更新新的符号表中每个符号的偏移量(运行时地址)
重定位节中的符号引用
- 链接器修改代码节和数据节中对每个符号的引用,使得它们指向正确的运行时地址,为了执行这一步,链接器依赖于重定位条目中的信息
typedef struct { |
ELF可执行的目标文件:
加载可执行文件
- 加载器运行时,在可执行文件的段头部表的指引下将可执行文件的相关内容拷贝到进程的虚拟地址空间所对应的内存中
- 跳转到程序的入口点也就是符号_start的地址,执行_start例程
0x080480c0 <_start>: /* Entry point int .text */ |
动态链接
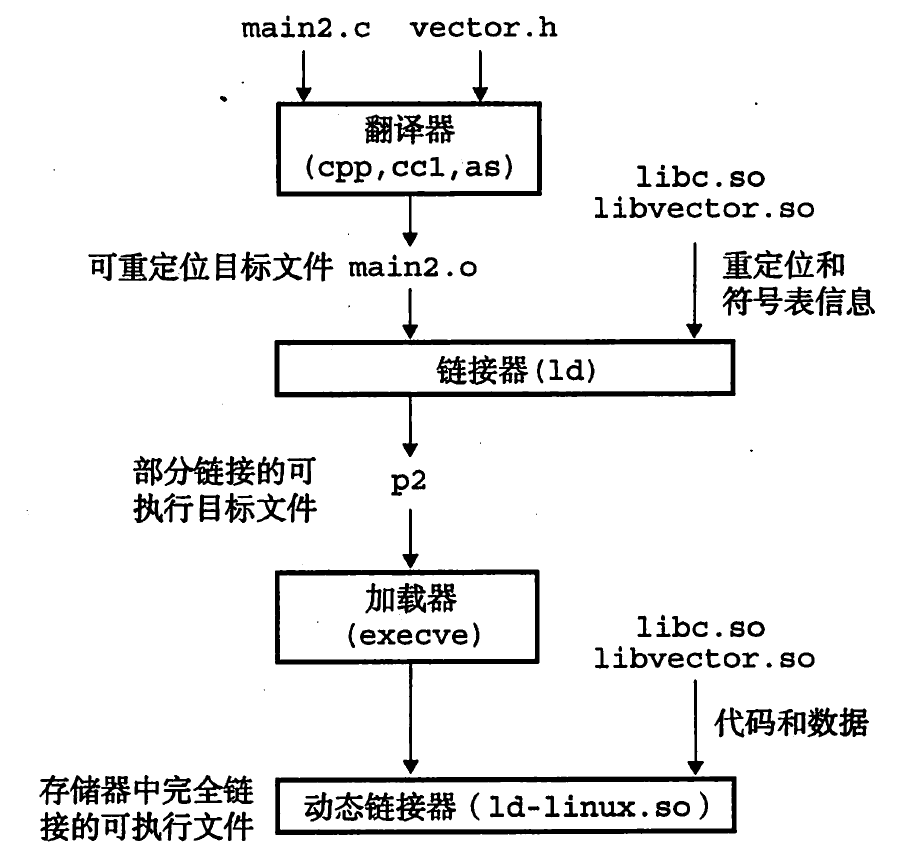
链接器与动态库链接的时候没有拷贝代码段和数据段,而是拷贝了一些符号表,并记录了每个需要重定位的符号的标识以及定义该符号的动态库的标识
与动态库链接生成的可执行的目标文件中多了一个.interp节,它包含动态链接器的路径,加载器加载的时候会识别这个节并运行动态链接器
动态链接器将动态库文件映射到可执行程序的虚拟地址空间的共享区域内,并重定位尚未解析的引用符号
- 数据符号在加载时重定位
- 函数符号在第一次调用的时候重定位
链接动态库与静态库相比在运行时效率会低一些
- 访问动态库中的全局数据需要3-5个指令,而静态库是1个指令
- 跳转到动态库函数入口地址时,第一次跳转需要5-10个指令,以后需要2个指令。而静态库链接的函数则只需要1个指令
动态库优点则是方便升级,节省内存空间